

What does insight look like?
Menimagerie is a place dedicated to capturing mental imagery from the wild and putting it on public display, like a glass menagerie of insight.
Its main means of doing so is through verbal and visual metaphor. To familiarise yourself with metaphor theory, read one of my essays on the topic.
Featured



Computer Science
Explore all the tantalising concepts in theoretical computer science - from our number system, via Cantor infinities, to Godel's theorems and automata - in these infographics from 2016.









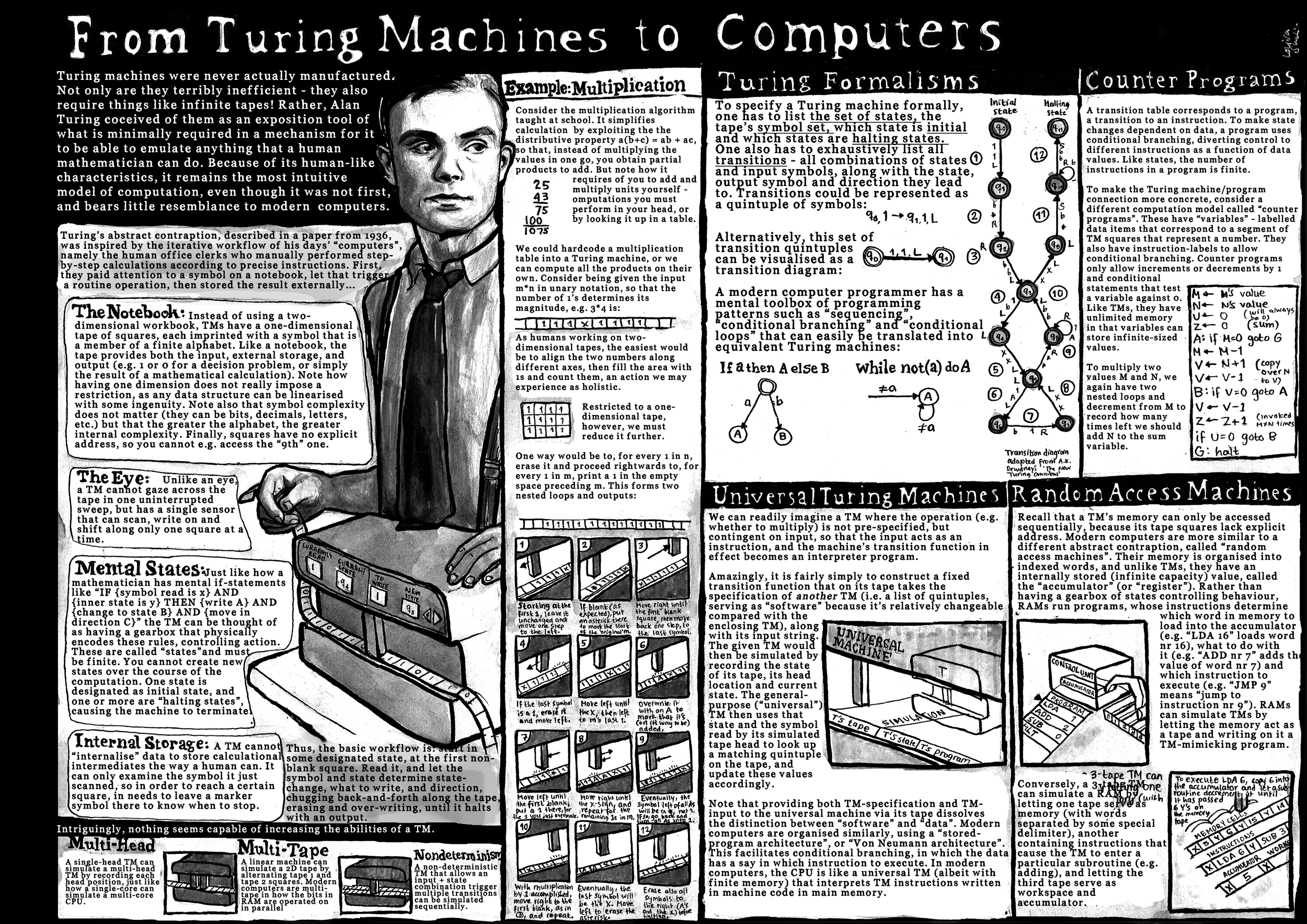


Algorithms
Explore common algorithms and automata in these lecture notes from 2016.















Natural History
Explore how the Age of Discovery led to collector mania across Europe, which eventually led to systematic classification approaches and culminated in the theory of natural selection.


















Astronomy
Coming soon: fanciful conceptions of the Universe by its inhabitants, from Babylonian ziggurat priests to the imperial courts of the Renaissance.

Statistics
An illustrated 13-part essay collection from 2015 on the philosophy of science, probability and statistics.
Featured














INFORMATION
A 9-part essay collection from the summer of 2015, about the interconnections between epistemology, information theory, thermodynamics, probability theory, and neuroscience.
Featured










HIERARCHY
My first collection, from the winter holiday of 2014, sets the tone for what's to come, with a gallery of concepts sourced from books in complexity theory.
Featured








LIBRARY
I am preparing for this place to be a list of reviews for the books that have played a formative role for Menimagarie. Until I finish it, explore my essays on information management.
Featured


- Albert Einstein
- Algorithmic probability
- Alpha level
- Aristotle
- Arthur Koestler
- Artificial intelligence
- Bayesian Statistics
- Beta level
- Categorization
- Causal Reasoning
- Central Limit Theorem
- Central Tendency
- Classification
- Claude Shannon
- Cognitive Closure
- Communication
- Complex Adaptive Systems
- Correlation
- Cost-benefit analysis
- Daniel C. Dennett
- David Hume
- David Weinberger
- Education
- Embodied cognition
- Entropy
- Ergodicity
- Eugene Wigner
- Evolution
- Experimental Design
- Explanation
- Falsificationism
- Frequentism
- Gerd Gigerenzer
- Halting problem
- Herbert A. Simon
- Heuristic
- Hillary Putnam
- Hindsight Bias
- History of Science
- Holon
- Howard Bloom
- Ian Stewart
- Immanuel Kant
- Induction
- James J. Gibson
- John Dewey
- John H. Holland
- Knowledge visualization
- Laplace’s demon
- Likelihood
- Likelihood Analysis
- Max Tegmark
- Measurement Theory
- Melanie Mitchell
- Metaphor
- Method of Loci
- Multiple comparisons
- Multiple testing
- Multiplier Effect
- Music
- Mutual information
- Near-decomposability
- Networks
- Noise
- Normal Distribution
- Null-hypothesis Significance Testing
- Occam's Razor
- Ontology
- Overfitting
- Parallel Terraced Scan
- Parameter
- Paul Davies
- Perception
- Peter Wason
- Philip Johnson-Laird
- Physics
- Possibility Space
- Power
- Power Law
- Probability Distribution
- Quantitative Research
- Quantum Physics
- Randomness
- Reductio Ad Absurdum
- Redundancy
- Religion
- René Descartes
- Scientometrics
- Self-information
- Standard Deviation
- Stephen Jay Gould
- Substance Theory
- Systems Theory
- T-test
- Thermodynamics
- Thomas Kuhn
- Trade-off
- Under-determination of Theory
- Unreasonable Effectiveness
- Variable

Fictions
Short parable stories that explore themes of signal, noise and self-reference.
Featured




About Me
My name is Lovisa Sundin, from Gothenburg (Sweden) and I am the writer and illustrator of the content on this website.
Photo by Andras Kovach
I have a degree in Computer Science and Psychology from the University of Glasgow and am currently doing a PhD at the same university.
I started Menimagerie as a labour of love during my second year at university. The idea was to construct a virtual museum for concepts I wished everyone knew about.
Since then, I have spent every holiday rushing home from work to plough through science books, take copious notes on their metaphors and then visualise them. It's been a sweaty, consuming, sometimes lonely hobby, but it means everything to me, and I am still working as hard as ever to turn Menimagerie into an intellectual adventure for others to join me on.
Thank you to everyone who has motivated me and supported me in this project: Magnus Hall, Philippe Schyns, Paul Cockshott, Patrick Prosser, Quintin Cutts, my dear lab friends, Tom Wallis for pushing me to do the website, and of course, Xavier.

I did a TEDx talk at my university where I encourage students to collect and visualise metaphors.
The computing revolution may have made the line graph of human progress look like a barely tilted horizon, broken by a near-vertical spurt.